same for AMD graphics since 2019. I wouldn't be surprised if Intel were doing the same with Arc too, though I haven't looked into that yet.
vikingtons
joined 1 year ago
yeah it's great to be in a community that has little tolerance for basic tossers
Really appreciate the insight
waiting for the name & shame. what an absolute tosser
Out of curiosity, how does dwl compare to dwm today?
Ah yeah, I'm not getting any response from https://archive.ph/ right now :/
E: got it working again after several attempts. Posting raw text
Archive link
Raw:
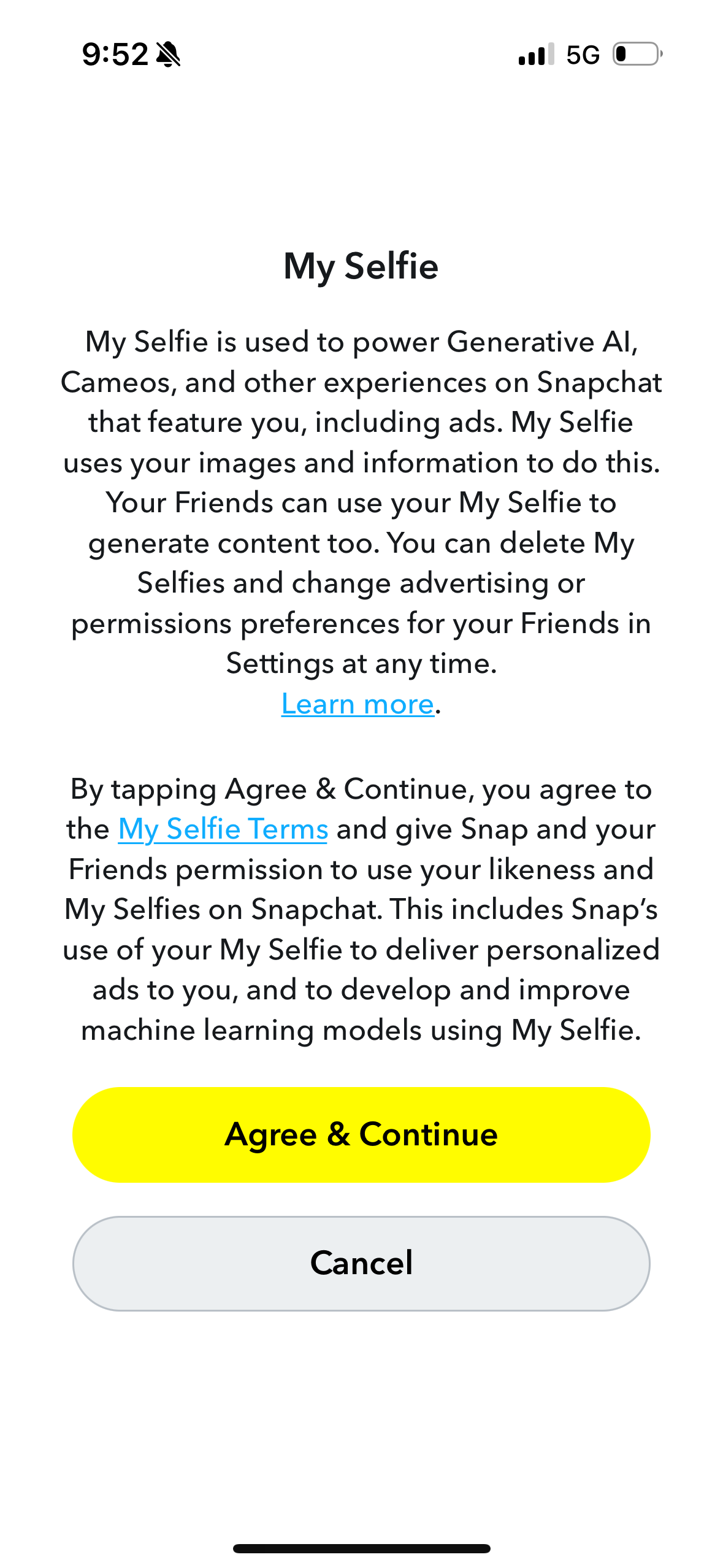
Snapchat is reserving the right to put its users’ faces in ads, according to terms of service related to its “My Selfie” tool (formerly “AI Selfies”), which allows users and their friends to create AI-generated images trained on their selfies. Users have the option to opt out of this by toggling off a “feature” in the app called “See My Selfie in Ads,” but according to 404 Media’s testing this feature is on by default.
“My Selfie is used to power Generative AI, Cameos and other experiences on Snapchat that feature you, including ads,” a pop up in the Snapchat app says. “My Selfie uses your images and information to do this.”
A support page on the Snapchat website titled “What is My Selfie?” explains further: “You’ll take selfies with your Snap camera or select images from your camera roll. These images will be used to understand what you look like to enable you, Snap and your friends to generate novel images of you. If you’re uploading images from the camera roll, only add images of yourself,” Snapchat’s site says. “After you've successfully onboarded, you may have access to some features powered by My Selfie, like Cameos stickers and AI Snaps. We are constantly adding features and functionality so stay tuned for more My Selfie features.”
After seeing the popup, I searched for instances of people getting ads featuring their own face on Snapchat, and found this thread on the r/Privacy Reddit community where a user claimed exactly this happened to them. In an email to 404 Media, Snapchat said that it couldn’t confirm or deny whether this user was served an ad featuring their face, but if they did, the ad was not using My Selfie images. Snapchat also said that it investigated the claim in the Reddit thread and that the advertiser, yourdreamdegree.com, has a history of advertising on Snapchat and that Snapchat believes the ad in question does not violate any of its policies.
“The photo that was used in the advertisement is clearly AI, however, it is very clearly me,” the Reddit user said. “It has my face, my hair, the clothing I wear, and even has my lamp & part of a painting on my wall in the background. I have no idea how they got photos of me to be able to generate this ad.”
(The Reddit user did not respond to a request for comment. yourdreamdegree.com did not respond to a request for comment.)
“You are correct that our terms do reserve the right, in the future, to offer advertising based on My Selfies in which a Snapchatter can see themselves in a generated image delivered to them,” a Snapchat spokesperson said. “As explained in the onboarding modal, Snapchatters have full control over this, and can turn this on and off in My Selfie Settings at any time.”
Snapchat emphasized that “Advertisers do not have access to Snapchatters’ Gen AI data in any capacity, including My Selfies. Nor do they have access to Snapchatters’ private data, including Memories, that would enable them to create an AI generated image of an individual Snapchatter.”
However, the company did not answer questions about how it could in the future serve ads featuring a user’s face without providing that data to advertisers. Instead, it replied that “Snap currently does not use My Selfies in advertising,” and that “the terms you cited simply reserve the right.”
Very true, just thinking about a terminal platform here, and just fully sending it off, but regular vermeer is no slouch either, and will serve well for many years to come (along with a shiny new gpu)
You could chuck a 57 or 5800X3D up in there for a substantial boost if your board vendor offers BIOS support.
This outlines several issues, a key one is outbidding apple for wafer alloc on leading processes. They primarily sell such high margin products that I suppose they can go full send on huge dies with no sweat. Similarly, the 4090's asking price was likely directly related to it's production cost. A chunky boy with a huge l2$.
I like the way Mike Clark frames challenges in semi eng as a balancing act between area, power, freq and performance (IPC); like a chip that's twice as fast but twice the size of its predecessor is not considered progress.
I wish ultra-efficient giga dies were more feasible but it's kind of rough when TSMC has been unmatched for so long. I gather Intel's diverting focus in 18A, and I hope that turns out well for them.
I'm not sure that arm as an ISA (or even RISC) is inherently more efficient than CISC today, particularly when we look at Qualcomm's latest efforts in notebooks, more that Apple have extremely proficient designers and benefit from vertical integration.
view more: next ›
Absolutely. They've been getting really popular in wearables (particularly from Chinese brands).
Several SBC vendors are including rv clusters in ARM based SoCs (which I believe is partially related to what you mentioned) for development purposes.
I even have a little rv powered ssoldering iron 😊