this post was submitted on 02 Oct 2023
1021 points (99.1% liked)
Programmer Humor
33569 readers
163 users here now
Post funny things about programming here! (Or just rant about your favourite programming language.)
Rules:
- Posts must be relevant to programming, programmers, or computer science.
- No NSFW content.
- Jokes must be in good taste. No hate speech, bigotry, etc.
founded 5 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
As far as I know, Stable Diffusion is a far smaller model than Llama. The fact that a model as large as LLaMa can even run on consumer hardware is a big achievement.
Both SD 1.5 and SDXL run on 4g cards, you really want fp16 though.
In principle it should be possible to get decentish performance out of e.g. an RX480 by using the (forced) 32-bit precision to do bigger winograd convolutions (severely reducing the number of
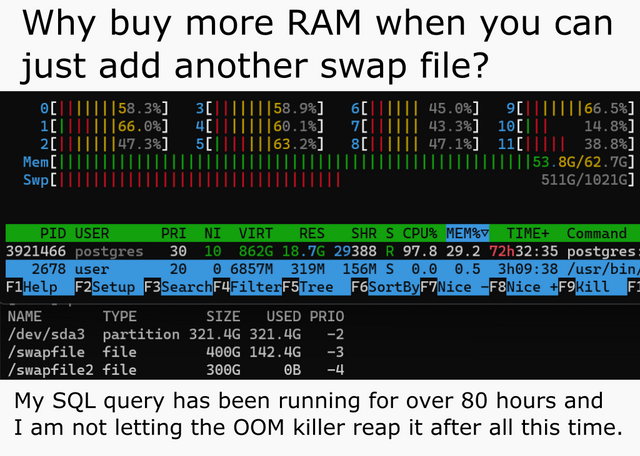
fmas needed) but don't expect AMD to write kernels for that, ROCm is barely working on mid range cards in the first place.Meanwhile, I actually ended up doubling my swap because 16G RAM are kinda borderline to merge SDXL models. OOM might kick in, it might not, and in any case your system is going to lock without earlyoom.
I had couple 13B models loaded in, it was ok. But I really wanted a 30B so I got a runpod. I'm using it for api, I did spot pricing and it's like $0.70/hour
I didn't know what to do with it at first, but when I found Simply Tavern I kinda got hooked.